Chapter 17 TFIH Exercises
Below you will find exercises relevant for the data analysis for the project work in the Thematic course in Food Innovation and Health. Exercises are meant as a guide on what you can do with your own data obtained through the practical work on the projects.
Before you start to work on the exercises, you need to familiarize yourself with the knowledge in the introduction chapters of this book as well as the chapters written specifically of for this course.
17.1 Exercise 1: Descriptive statistics and plots
From this exercise you should be able to describe the products in terms of common, rare and differential attributes, as well as the hedonic ratings.
17.2 Exercise 2: Consumer background and PCA
From this exercise you should be able to describe who your consumers are.
17.2.1 Demographics
Age, Gender, Income and Household size is classical demographic characteristics. As the evaluation of the products is done using a specific group of people, the generalizability of the results naturally condition of the characteristics of this population.
Construct the distributions of the demographic characteristics. You can use the table() function, or maybe do it all at once using the tableone package. For inspiration, modify the code below to serve your needs.
Is there any demographic bias in this dataset?
17.2.2 PCA on Interests
Calculate a PCA model including the Variables 7 ( Interest in food ) to 12 ( Future interest in beer ). Remember to standardize/scale the variables
Plot the scores and loadings in a biplot and look for groupings of the consumers in the scores.
Group and color according to the background information not used in the model (Gender, Age,..)
Describe what you find: For instance, is the loading making sense?
17.3 Exercise 3: PCA on CATA counts
From this exercise you should be able to describe your samples (beers) from the summed CATA counts (see the Chapter on “PCA on CATA data”), and which attributes that occur together, as well as which attribute patterns that discriminate products.
Calculate a PCA model including all Variables and all Objects.
beercatasum <- beercata %>%
pivot_longer(names_to = 'attrib',values_to = 'val', cols = S_Flowers:S_Vinous) %>%
group_by(Beer,attrib) %>%
summarize(n = sum(val)) %>%
pivot_wider(names_from = attrib, values_from = n)
PCAmdl <- prcomp(beercatasum[,-1], scale. = T)Plot the scores and describe the groupings of the samples.
Plot the loadings and describe the correlations between the variables.
Both of these plots are present in a biplot, but you may want to play around with the settings (such as labels.size, varname.size, varname.adjust, …) to get all information out.
Use this biplot to find out which samples are described by which CATA attributes. as well as similarity of products.
17.4 Exercise 4: Cochran’s Q test on CATA binary data
In Exercise 1 the attributes characteristic for certain products, were summarized using descriptive stats and plots. Now we want to add statistical inference onto these observations.
To get started, choose a few attributes. For each attribute 1) Perform Cochran’s Q test for overall difference, and if interesting enough 2) perform a Post hoc test for product segmentation.
To get all attributes analyzed collectively, use the tidyverse code in the chapter For all attributes in one run (nice to know).
Which descriptors are most different between products? Are the overall most pronounced descriptors also the ones most different?
Try this procedure out on a different dataset, e.g. the tempeto data.
17.5 Exercise 5: Hedonic ratings and consumer characteristics
From this exercise you should be able to describe the liking of the beer samples and glimpse into consumer characteristics related to liking
17.5.1 PCA on joint data
Calculate a PCA model including liking for all beers.
beerliking_wider <- beerliking %>%
pivot_wider(names_from = Beer,values_from = Liking) %>% # make into wide format
drop_na()
PCAliking <- prcomp(beerliking_wider[,13:18], scale. = T)Plot a biplot or loading plot, and use the loadings and describe the correlations between the variables (liking of beers in this case).
Plot the scores and describe the groupings of the samples by colouring the score plot according to the consumer background variables.
Any trends? For instance, how is liking related to the individual consumer diversity of beer ( Beer types/month)?
17.5.2 All demographics
… Some code to get all 7-scale demo information plots. You may want to export and view in a pdf viewer for zooming etc.
gall <- cbind(PCAliking$x[,1:2], beerliking_wider) %>%
pivot_longer(names_to = 'var',values_to = 'val',cols = `Interest in food`:`Future interest in beer`) %>%
ggplot(data = ., aes(PC1,PC2, color = factor(val))) +
geom_point() +
stat_ellipse() +
facet_wrap(~var)
ggsave(filename = 'anicebigfigure.pdf',gall, height = 20, width = 20)17.6 Exercise 6: PCA on CATA counts and hedonic ratings
From this exercise you should be able to conclude what attributes that overall drives the liking of products (beers).
For each beer, the collated CATA counts and the averaged liking constitutes the multivariate response matrix.
likingsum <- beerliking %>%
group_by(Beer) %>%
summarize(Liking = mean(Liking, na.rm = T))
catasum <- beercata %>%
pivot_longer(names_to = 'attrib',values_to = 'val', cols = S_Flowers:S_Vinous) %>%
group_by(Beer,attrib) %>%
summarize(n = sum(val, na.rm = T)) %>%
pivot_wider(names_from = attrib, values_from = n)Join the two.
Do a PCA
What charaterizes River Beer ? Which descriptors are in general associated with liking? (and dis-liking?)
17.7 Exercise 7: Mixed modelling on hedonic ratings
In this exercise we want to model Liking as a response. We want to use the beer type as the main predictor, but take into account that the responses is repeated within consumers. The same judges have evaluated all beers. This is a mixed model
Start with a plot
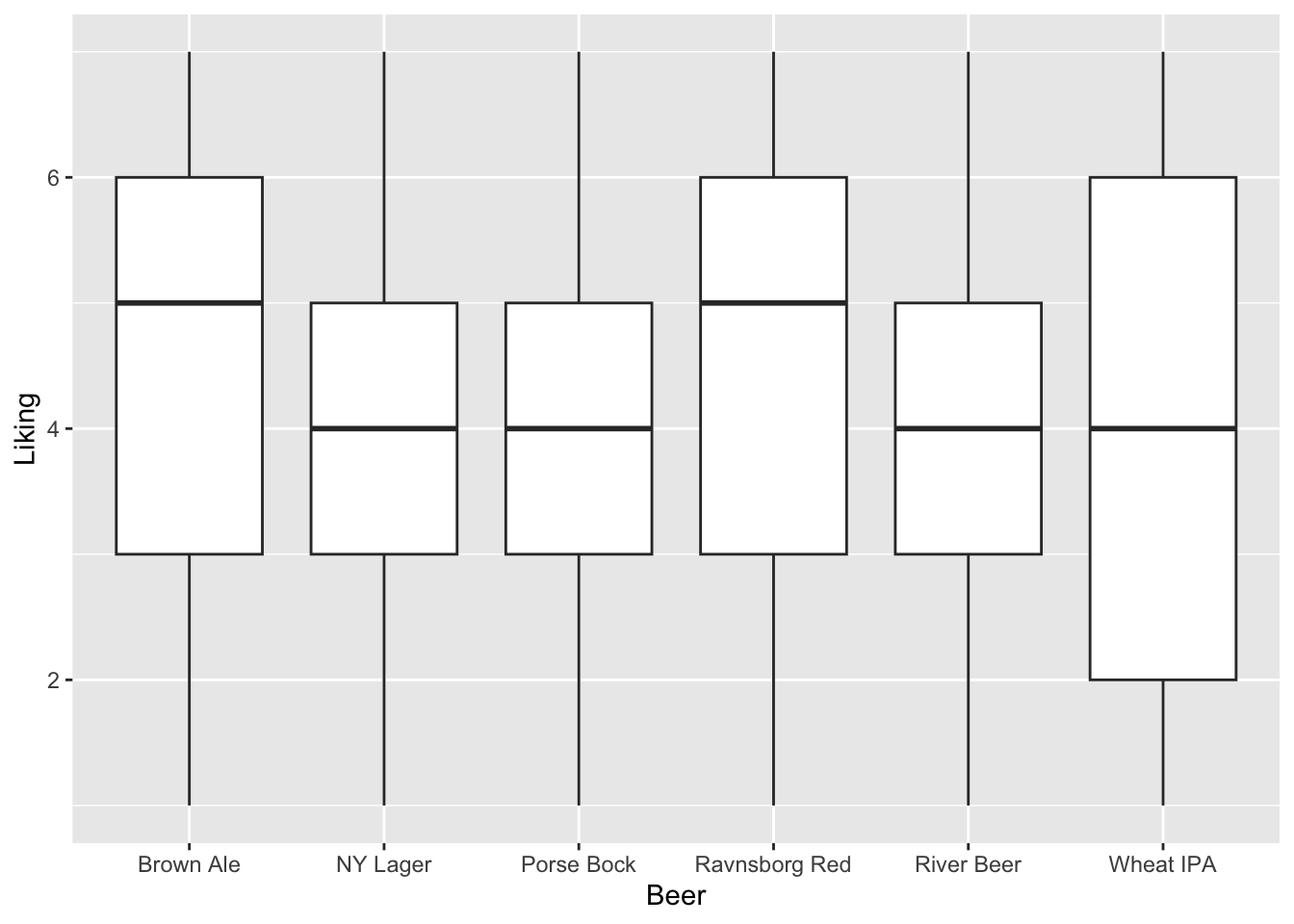
Evaluate this model by anova() and summary(), and interpret the result. How much within individual consumer variation is there compared to between consumer?
You should get that the beers are not equally likable. But are there maybe some which are more similar? Perform a all-pairs post hoc test and try to group beers based on liking.
Try to add consumer demographics and interest to the model to evaluate general consumer patterns as well as interactions with beer type.
Try to answer questions such as:
- Are there any significant product differences for the liking? If so, what does the post hoc test tell us? How does this fit with what you have done in the PCA exercises.
- Is the liking in general affected by the age, gender, household size or beer knowledge? What is the effect? Try to think of a plot that can show the significant differences.
- Do men and women score the samples significantly different in liking? Calculate the sample/gender differences in averages.