Chapter 10 Consumer segmentation
The data used in the first part of this chapter is from the paper: Verbeke, Wim, Federico JA Pérez-Cueto, and Klaus G. Grunert. “To eat or not to eat pork, how frequently and how varied? Insights from the quantitative Q-PorkChains consumer survey in four European countries.” Meat science 88.4 (2011): 619-626. and can be found in the data4consumerscience-package as pork.
10.1 Segmentation
To create the consumer segments, a cluster analysis, based on behavioral data (frequency and variety of consumption), will be carried out.
This example shows k-means clustering as the clustering analysis, but there are many more options out there - some more data-driven and some using common sense or domain knowledge. Both types of segmentation can be valid, as long as the scientific reasoning behind makes sense.
10.1.1 Using K-means for clustering
K-means is a popular algorithm used for clustering, which is a fancy word for grouping. This means, that we can group un-grouped data, if the different attributes create such groups.
The algorithm works by you selecting a value for “k,” which is the number of clusters/groups that the algorithm will attempt to group the data points into. Then, it randomly selects “k” points from the dataset as the initial centroids. These centroids represent the centers of each cluster.
Next, the algorithm iteratively assigns each data point to the nearest centroid based on the squared Euclidean distance between the point and the centroid (also known as the “Within Cluster Sum of Squares”(WCSS)). After all data points have been assigned, the centroid for each cluster is recalculated by taking the mean of all the points assigned to that cluster. This step updates the center of each cluster.
The algorithm repeats the previous two steps until the centroids no longer move or the maximum number of iterations is reached. The final result is a set of “k” clusters, where each data point belongs to the cluster with the closest centroid.
K-means in R is pretty simple - only one line of code is needed to perform the analysis, if the data are ready for analysis.
First, we set.seed. As k-means is an iterative algorithm, that starts in a random point, it matters where this point is. Usually, the only thing happening if the seed is changed, is that the order of the clusters change - but this can be annoying enough that you would want to avoid it! To ensure, that we get the same results every time we run the algorithm, we set the seed, and keep it that way throughout the analysis.
As a start, we only use two variables (specified in the code as “VarietyTotal” & “TotalPorkWeek”, from the dataset pork), as this is easy to interpret. Below is shown an example with both 2 and 3 clusters (“centers = _“).
The “nstart”-input specifies, that the clustering will start at 25 different random points, and selects the best. Doing this will help getting the same result every time, especially if data are less clustered by nature. For details on the algorithm type ?kmeans to get help.
Note, the set.seed(123) is only for reproducibility and hence only nice-to-know.
set.seed(123)
km.cluster3 <- kmeans(pork[, c("VarietyTotal", "TotalPorkWeek")], centers = 3,nstart = 25)
km.cluster2 <- kmeans(pork[, c("VarietyTotal", "TotalPorkWeek")], centers = 2,nstart = 25)First, we run a clustering with the function kmeans for the dataset pork. We will use the two variables “VarietyTotal” & “TotalPorkWeek” to calculate the three best clusters, and we will choose the random centers 25 times, by specifying the argument nstart. You can off course change this number yourself. We save it as km.cluster3 (remember you choose this name). Secondly, we run almost the same clustering, changing only the name and the number of centers to 2.
10.1.2 Initial characterization of clusters
Below are some of the outputs, that you can get from the clustering. Here you can see the size of the clusters as well as the positions of their centroids. Positions here means the value of the centroid for each variable. For example, below we see, that the cluster 1’s centriod has a value for VarietyTotal of 25.04562. Size means the number of members in each cluster.
Here for 3 clusters:
## VarietyTotal TotalPorkWeek
## 1 27.10061 22.969634
## 2 22.85949 4.957372
## 3 27.26288 11.343699## [1] 328 548 757… and for 2 clusters:
## VarietyTotal TotalPorkWeek
## 1 25.04562 7.571986
## 2 27.28738 20.140544## [1] 1118 515Centers will give you the average values for the variables “VarietyTotal” & “TotalPorkWeek” in the center of each of the three (in km.cluster3) clusters. Size will give you the the number of members per cluster. It is a good idea to check that the clusters are not too uneven in number of members. The third line above is just another way of asking for the size of the clusters in km.cluster3. All command are repeated for the km.cluster2; that is the cluster analysis with two clusters, you made and saved above.
10.1.3 Vizualization of the clusters
It is, however, a lot easier to understand clustering, when it is visualized. Below is shown two different ways of plotting the clusters - one using the build-in plotting function, and one using the package ggplot2. ggplot2 maybe looks a bit more complicated, but has a lot of functions built into it, which means that it can be nice to learn!
Try to make the plots yourself, and try to see what happens if you change different inputs.
Using Basic R-plotting
plot(TotalPorkWeek ~ VarietyTotal, data = pork, col = km.cluster3[["cluster"]] + 1)
points(km.cluster3[["centers"]], pch = 20, cex = 1.3)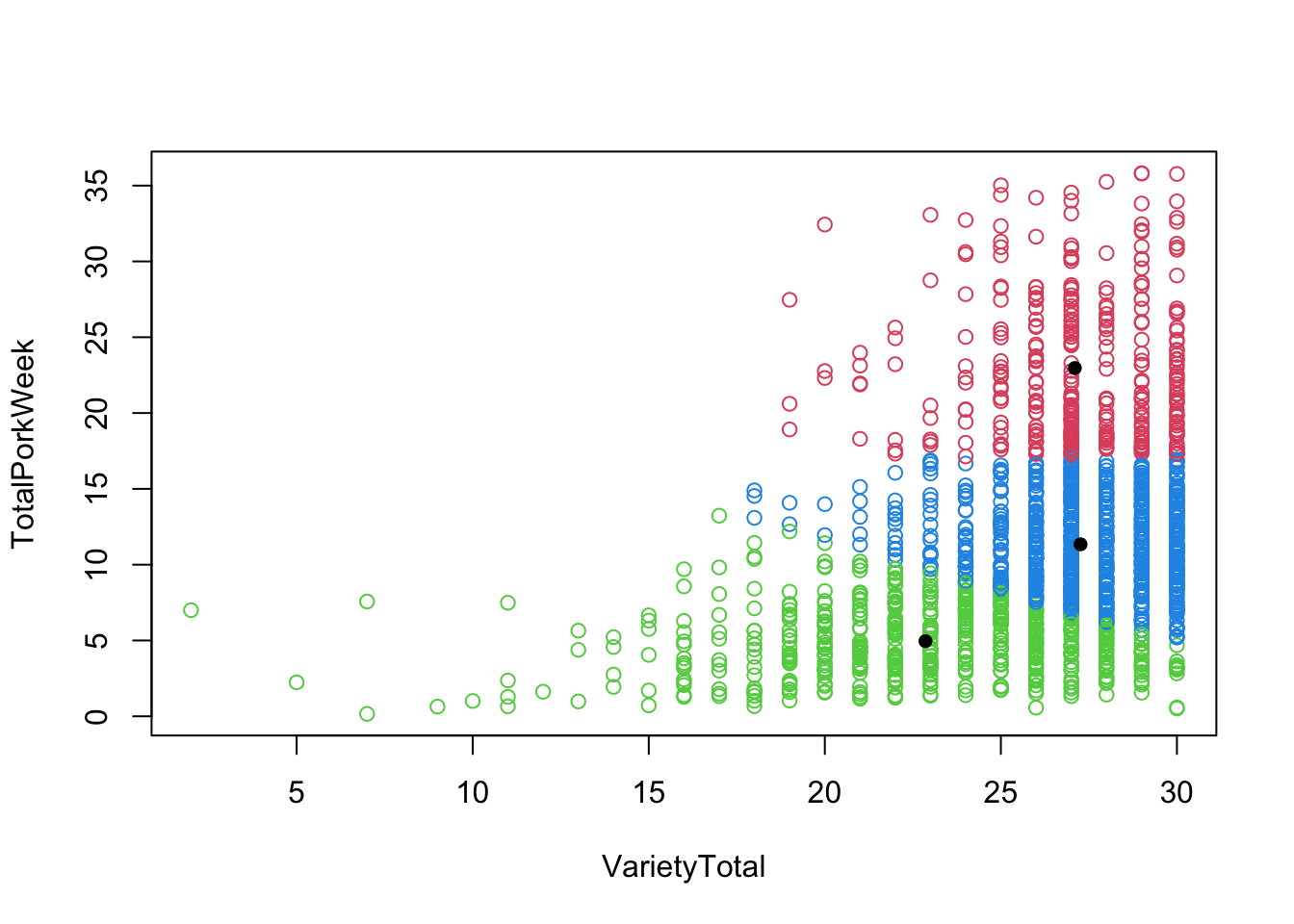
The first line creates a scatter plot, by plotting the variables TotalPorkWeek on the y-axis and VarietyTotal on the x-axis. points() function adds the cluster centers as points from the km.clusters3 object to the existing scatter plot. The pch argument specifies the point type, and the cex argument controls the size of the point.
Using ggplot2 with 3 centers
library(ggplot2)
df <- data.frame(km.cluster3[["centers"]])
df2 <- data.frame(km.cluster2[["centers"]])
#ggplot 2
ggplot(data = pork, aes(x = VarietyTotal, y = TotalPorkWeek)) +
geom_point(aes(color = factor(km.cluster3$cluster))) +
guides(color = guide_legend('Cluster')) +
geom_point(data = df,
aes(x = VarietyTotal, y = TotalPorkWeek),
color = 'black',
size = 2) +
theme_linedraw()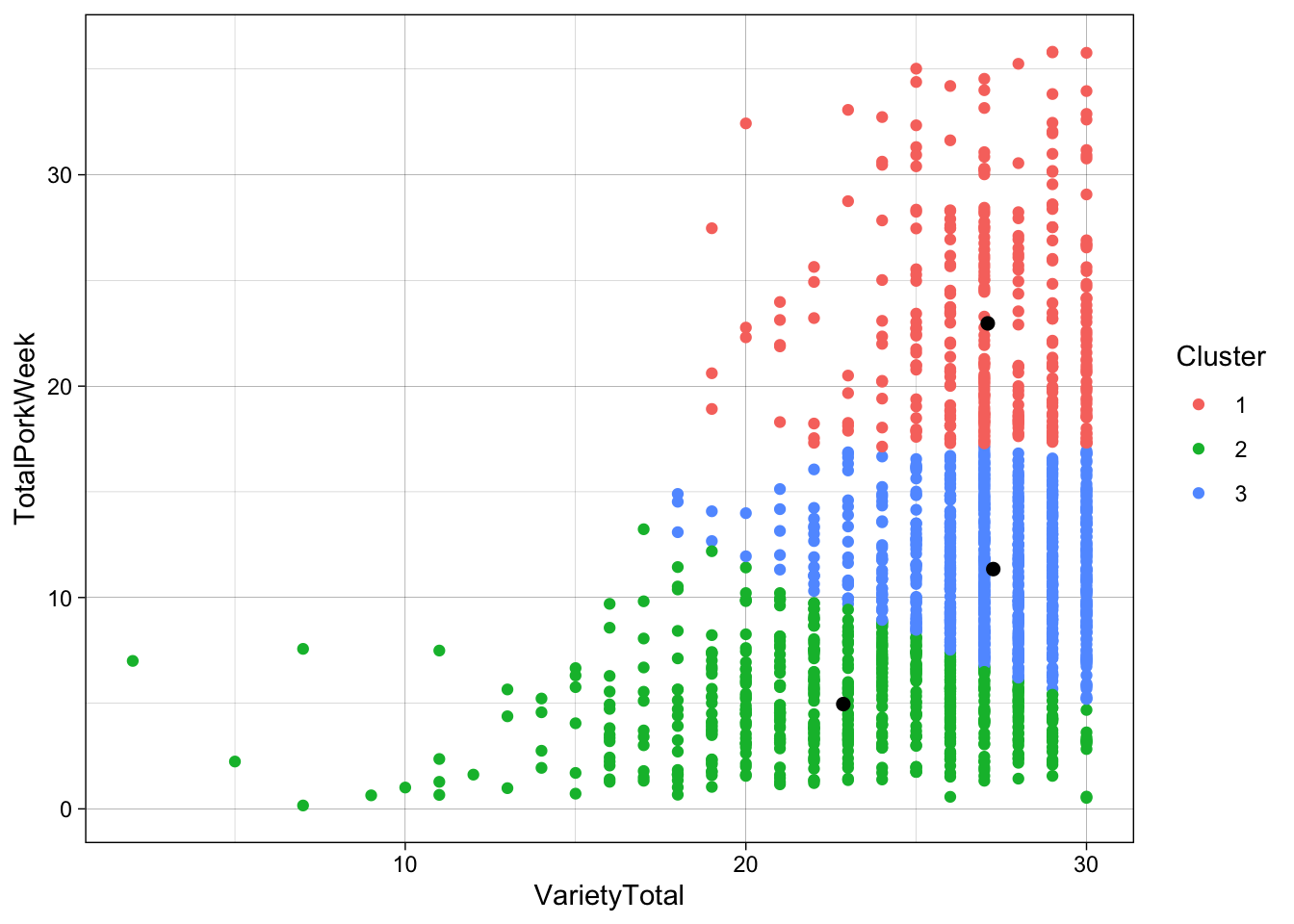 When using ggplot2, as data frame is needed. Therefore two data frames a made, one for each of the centers from the clustering objects previously made.
ggplot creates a scatter plot using the pork data, with the variables TotalPorkWeek on the y-axis and VarietyTotal on the x-axis.
geom_point() adds the first layer of points. These points are colored according to the clusters in km.cluster3. factor() is used to ensure that the cluster variable is treated as a categorical variable.
guides() modifies the legend title for the color guide in the plot. It changes the legend title to “Cluster.”
geom_point() adds the second layer of points to the plot using the df data frame. These points represent the cluster centers.
When using ggplot2, as data frame is needed. Therefore two data frames a made, one for each of the centers from the clustering objects previously made.
ggplot creates a scatter plot using the pork data, with the variables TotalPorkWeek on the y-axis and VarietyTotal on the x-axis.
geom_point() adds the first layer of points. These points are colored according to the clusters in km.cluster3. factor() is used to ensure that the cluster variable is treated as a categorical variable.
guides() modifies the legend title for the color guide in the plot. It changes the legend title to “Cluster.”
geom_point() adds the second layer of points to the plot using the df data frame. These points represent the cluster centers.
Using ggplot2 with 2 centers
ggplot(data = pork, aes(x = VarietyTotal, y = TotalPorkWeek)) +
geom_point(aes(color = factor(km.cluster2$cluster))) +
guides(color = guide_legend('Cluster')) +
geom_point(data = df2,
aes(x = VarietyTotal, y = TotalPorkWeek),
color = 'black',
size = 2) +
theme_linedraw()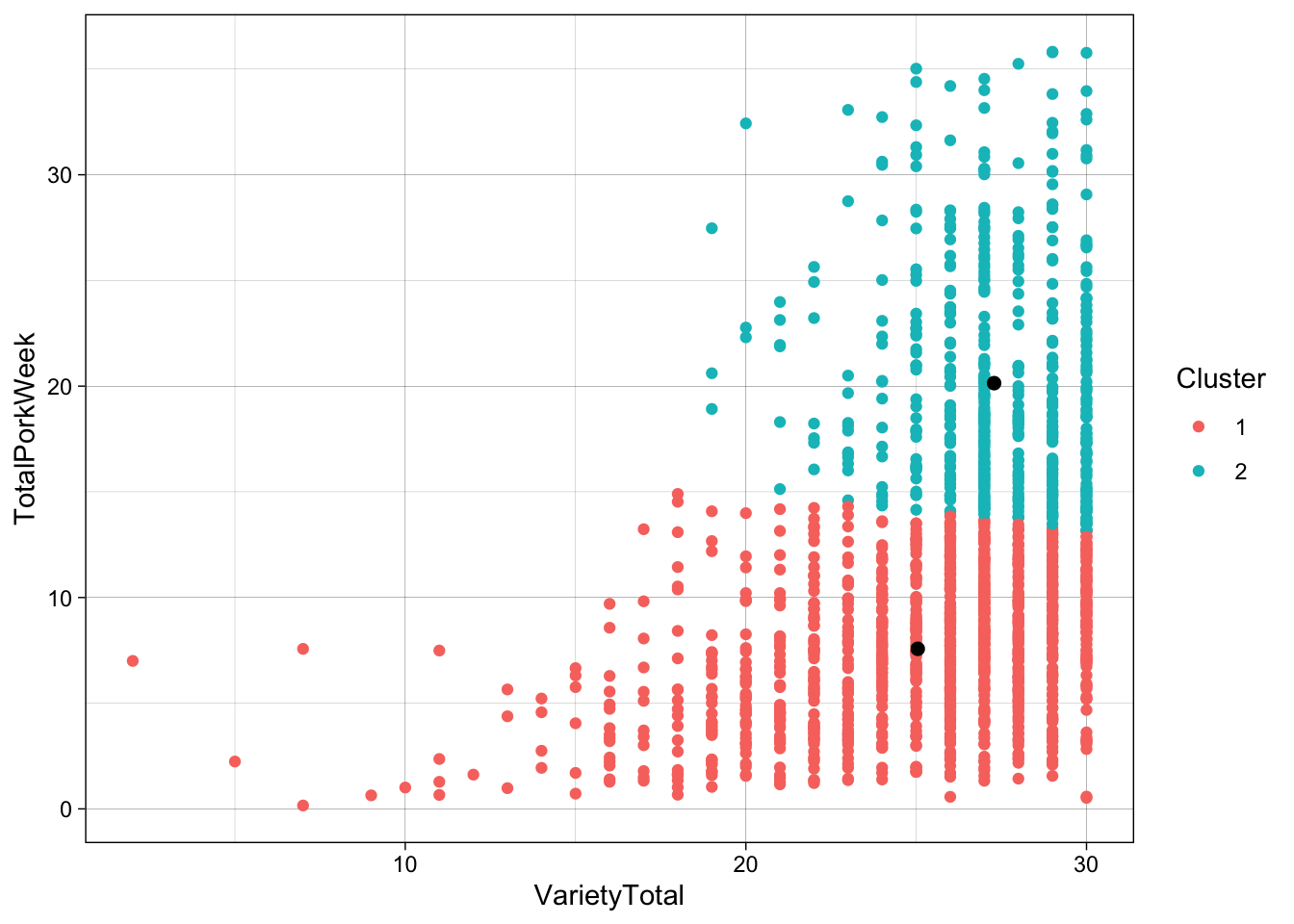 The method for creating the ggplot with 2 centers, is the same, only changing the data frame being used, when adding the second layer of points.
The method for creating the ggplot with 2 centers, is the same, only changing the data frame being used, when adding the second layer of points.
10.1.4 Sums of Squares from the clustering
As mentioned in [K-means], k-means set the clusters such that the between clusters (sort of differences between centers) are large while the distance within a cluster (from each sample to is cluster-center) is small.
R can also display these numbers, as shown below:
## [1] 9293.210 12534.737 9854.921## [1] 31682.87## [1] 73532.8110.2 Selecting the number of clusters - a data-driven approach
Usually there is no given set of clusters, so we want to also learn that from data.
Below we show how to use the Gap-statistics (from the cluster-package) for \(2\) up to \(10\) clusters to select the optimal number of clusters.
The concept of Gap statistics is based on the idea that if a dataset truly contains distinct clusters, then the dispersion within each cluster should be smaller than the dispersion between clusters. The gap statistic measures the difference between the observed dispersion and the expected dispersion under a null reference distribution. By comparing this gap statistic for different numbers of clusters, one can identify the optimal number of clusters that best captures the underlying structure of the data.
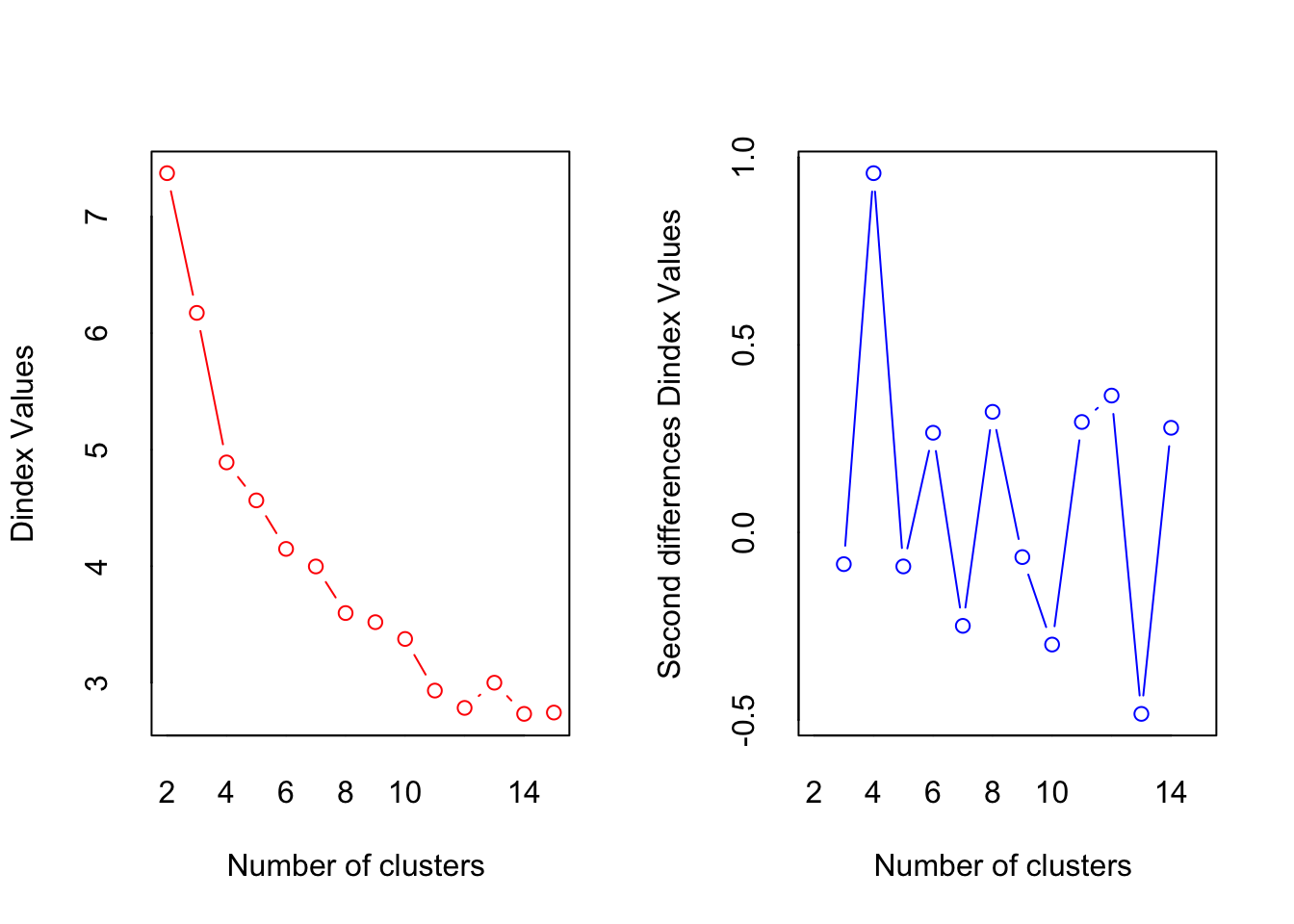
You don’t need to fully understand how it works, but you have to know how to interpret the plot, to be able to decide the number of clusters.
When interpreting the plot, the highest Gap-value (the y-axis) shows the number of clusters, that best represent the data. However, since we are trying to use the data to as a generalization of a larger population, one should be conservative when choosing the number of clusters. If a less complicated/more general model (less clusters) can explain almost the same, one should always choose the less complicated model.
As a rule of thumb, when interpreting the Gap-statistics plot, a model with a number of clusters within the standard deviation of the model with the best Gap-statistic will be sufficient. In our case, this means, that a model with 3 clusters should do the job, as seen below.
Another check is of course to make both models, and plot it, to check if the clustering makes sense. This is equally as important as looking at the Gap-statistics.
library(cluster)
gapStatistic <- clusGap(pork[, c("VarietyTotal", "TotalPorkWeek")], kmeans, 10)
plot(gapStatistic, main = "")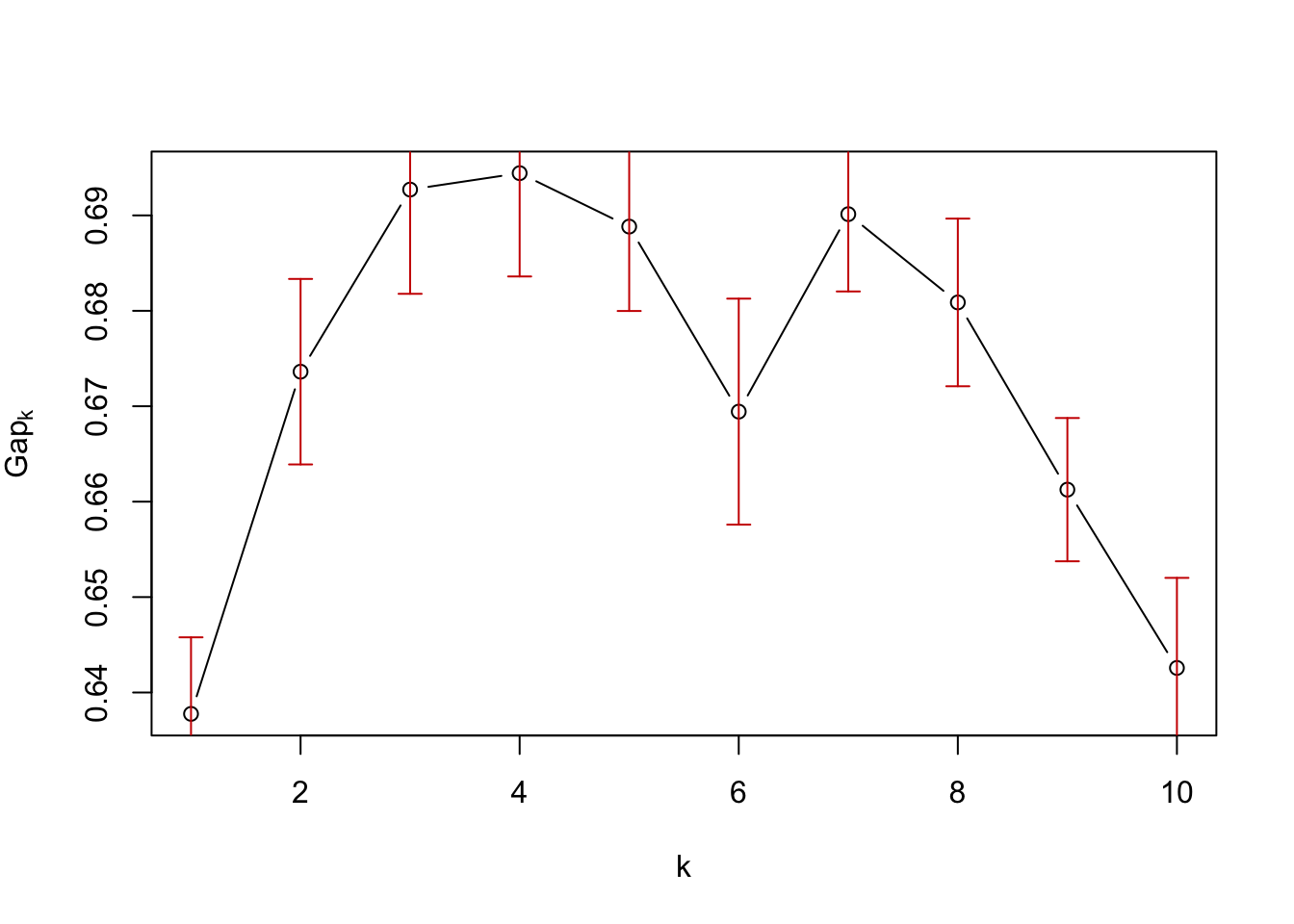 The package cluster is initially loaded. The gap statistics is then calculated using the function clusGap(), with the data pork and only containing the columns TotalPorkWeek and VarietyTotal, kmeans is used as the clustering algorithm. The 10 specifies that the analysis is performed for up to 10 clusters. The plot() function is then used to plot the results.
The package cluster is initially loaded. The gap statistics is then calculated using the function clusGap(), with the data pork and only containing the columns TotalPorkWeek and VarietyTotal, kmeans is used as the clustering algorithm. The 10 specifies that the analysis is performed for up to 10 clusters. The plot() function is then used to plot the results.
The point at which the gap statistic starts to level off or decrease can provide insight into the appropriate number of clusters to use for the data. Therefore the appropiate number of clusters seems to be \(10\)
Using Nbclust
Another package able to aid when trying to determine the number of clusters is NbClust. This package runs a variety of different tests, each resulting in an optimal number of clusters. This means, that while you get a lot of opinion on the number of clusters, the NbClust-function might take a while to run.
NbClust will show a lot of plots and show results for the different methods. You can look at them if you want, but the most important part is the last output of the function, where the voting for the different number of clusters as well as the conclusion is displayed.
library(NbClust)
Nbclusters <- NbClust(pork[, c("VarietyTotal", "TotalPorkWeek")], method = 'kmeans' )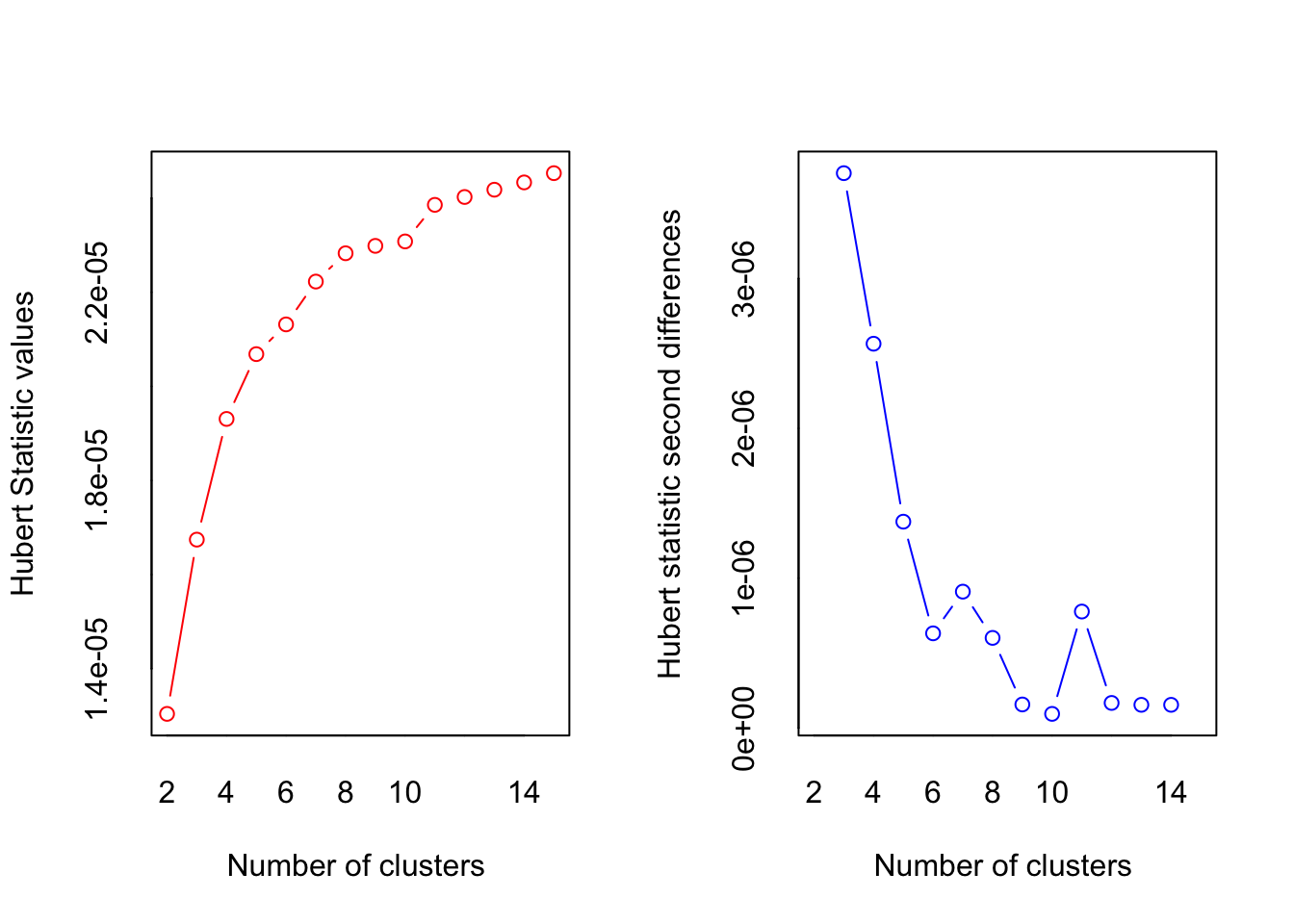
## *** : The Hubert index is a graphical method of determining the number of clusters.
## In the plot of Hubert index, we seek a significant knee that corresponds to a
## significant increase of the value of the measure i.e the significant peak in Hubert
## index second differences plot.
## 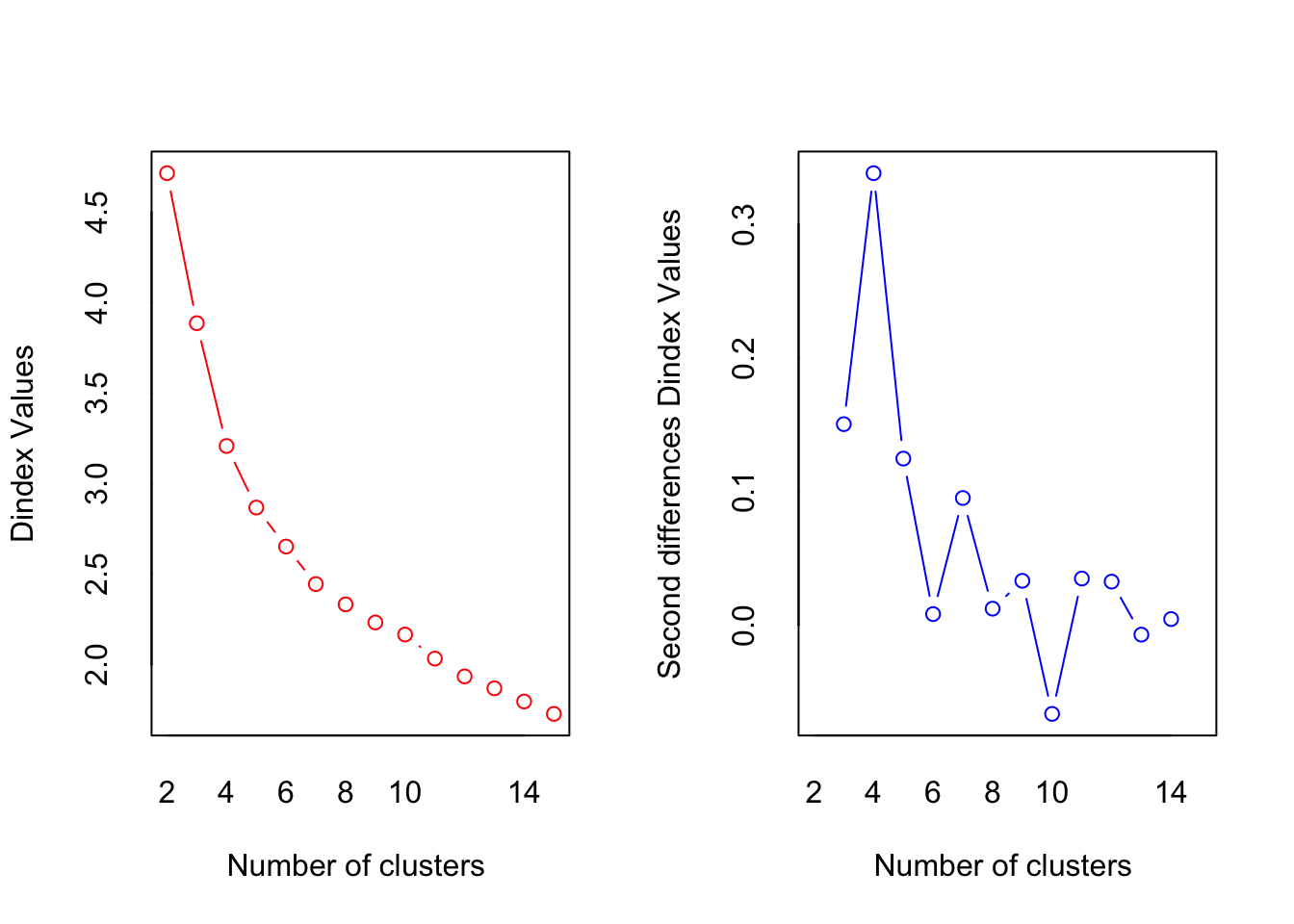
## *** : The D index is a graphical method of determining the number of clusters.
## In the plot of D index, we seek a significant knee (the significant peak in Dindex
## second differences plot) that corresponds to a significant increase of the value of
## the measure.
##
## *******************************************************************
## * Among all indices:
## * 10 proposed 2 as the best number of clusters
## * 3 proposed 3 as the best number of clusters
## * 6 proposed 4 as the best number of clusters
## * 1 proposed 10 as the best number of clusters
## * 2 proposed 11 as the best number of clusters
## * 2 proposed 13 as the best number of clusters
##
## ***** Conclusion *****
##
## * According to the majority rule, the best number of clusters is 2
##
##
## *******************************************************************The gap-statistics seems to suggest k=3, whereas NbClust suggests k=2-4, which shows how important it is, that you know your data enough to be able to make the right decision, such as number of clusters.
The rule of thumb is to use these data driven approaches together with interpretability of the resulting clusters, such that the solution is meaningful.
10.3 Segmentation - another example
The data plantbaseddiet constitute data from the following study, and can be found in the data4consumerscience-package:
Reipurth, Malou FS, Lasse Hørby, Charlotte G. Gregersen, Astrid Bonke, and Federico JA Perez Cueto. “Barriers and facilitators towards adopting a more plant-based diet in a sample of Danish consumers.” Food quality and preference 73 (2019): 288-292.
These we will use as a second example for cluster analysis.
10.3.1 Cluster analysis
In this example, 3 variables are included in the clustering: ‘a_meat’, ‘a_dairy’ and ‘a_eggs’. Otherwise, the same procedure applies: Finding the appropriate amount of clusters, and running the analysis.
library(cluster)
library(NbClust)
gapStatistic <- clusGap(plantbaseddiet[,c('a_meat', 'a_dairy','a_eggs')], kmeans, 10)
plot(gapStatistic, main = "")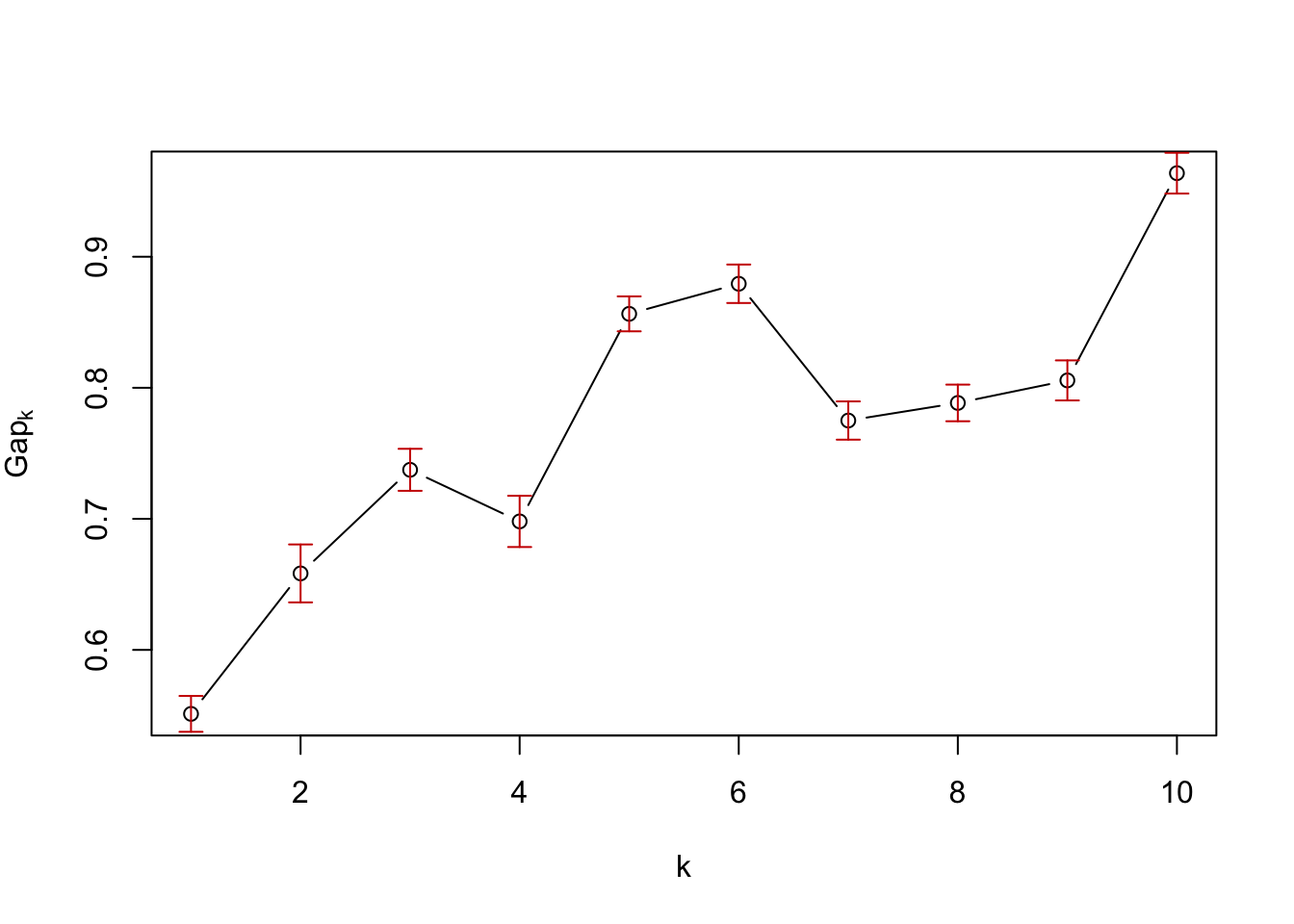
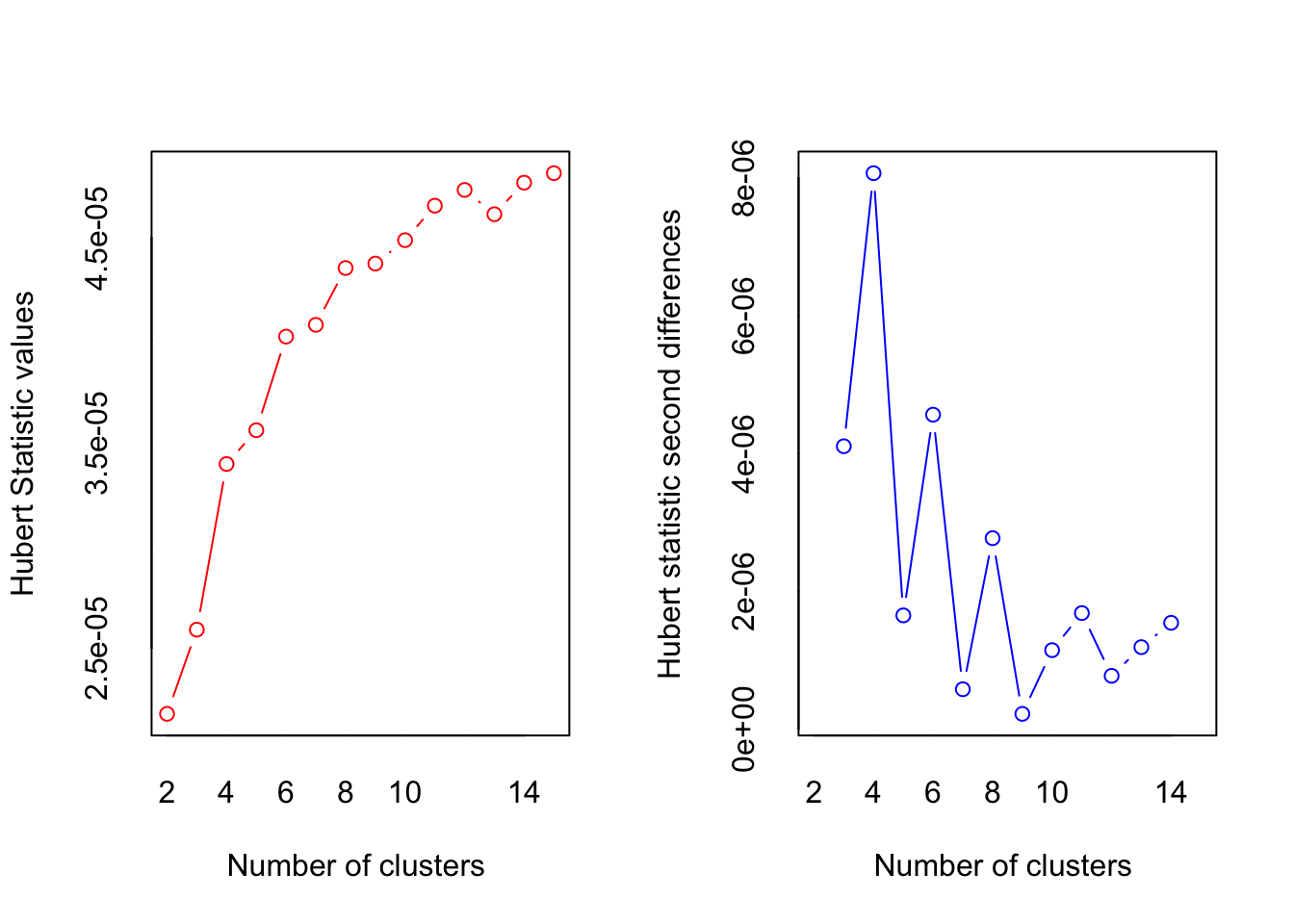
## *** : The Hubert index is a graphical method of determining the number of clusters.
## In the plot of Hubert index, we seek a significant knee that corresponds to a
## significant increase of the value of the measure i.e the significant peak in Hubert
## index second differences plot.
## 
## *** : The D index is a graphical method of determining the number of clusters.
## In the plot of D index, we seek a significant knee (the significant peak in Dindex
## second differences plot) that corresponds to a significant increase of the value of
## the measure.
##
## *******************************************************************
## * Among all indices:
## * 4 proposed 2 as the best number of clusters
## * 2 proposed 3 as the best number of clusters
## * 8 proposed 4 as the best number of clusters
## * 1 proposed 5 as the best number of clusters
## * 1 proposed 8 as the best number of clusters
## * 2 proposed 11 as the best number of clusters
## * 1 proposed 12 as the best number of clusters
## * 3 proposed 14 as the best number of clusters
## * 1 proposed 15 as the best number of clusters
##
## ***** Conclusion *****
##
## * According to the majority rule, the best number of clusters is 4
##
##
## *******************************************************************10.3.2 Plot the model using PCA
The thing is, that now that we are dealing with more than 2 dimensions, it can be harder to visualize, how well the clustering has worked. One way though, is to use Principal Component Analysis (PCA), as PCA aims to describe the most variance from the data as possible, in the fewest dimensions as possible. This means, that if indeed the clusters are a result of variation in the data, a PCA should show it.
For more information on PCA, see Introduction to PCA and multivariate data.
A PCA with the same data as the clustering is created (using the prcomp) and plotted (using ggbiplot)
library(ggbiplot)
PCAmdl <- prcomp(plantbaseddiet[,c('a_meat', 'a_dairy','a_eggs')], center = T, scale. = F)
ggbiplot(PCAmdl, groups = factor(res$cluster), ellipse = T)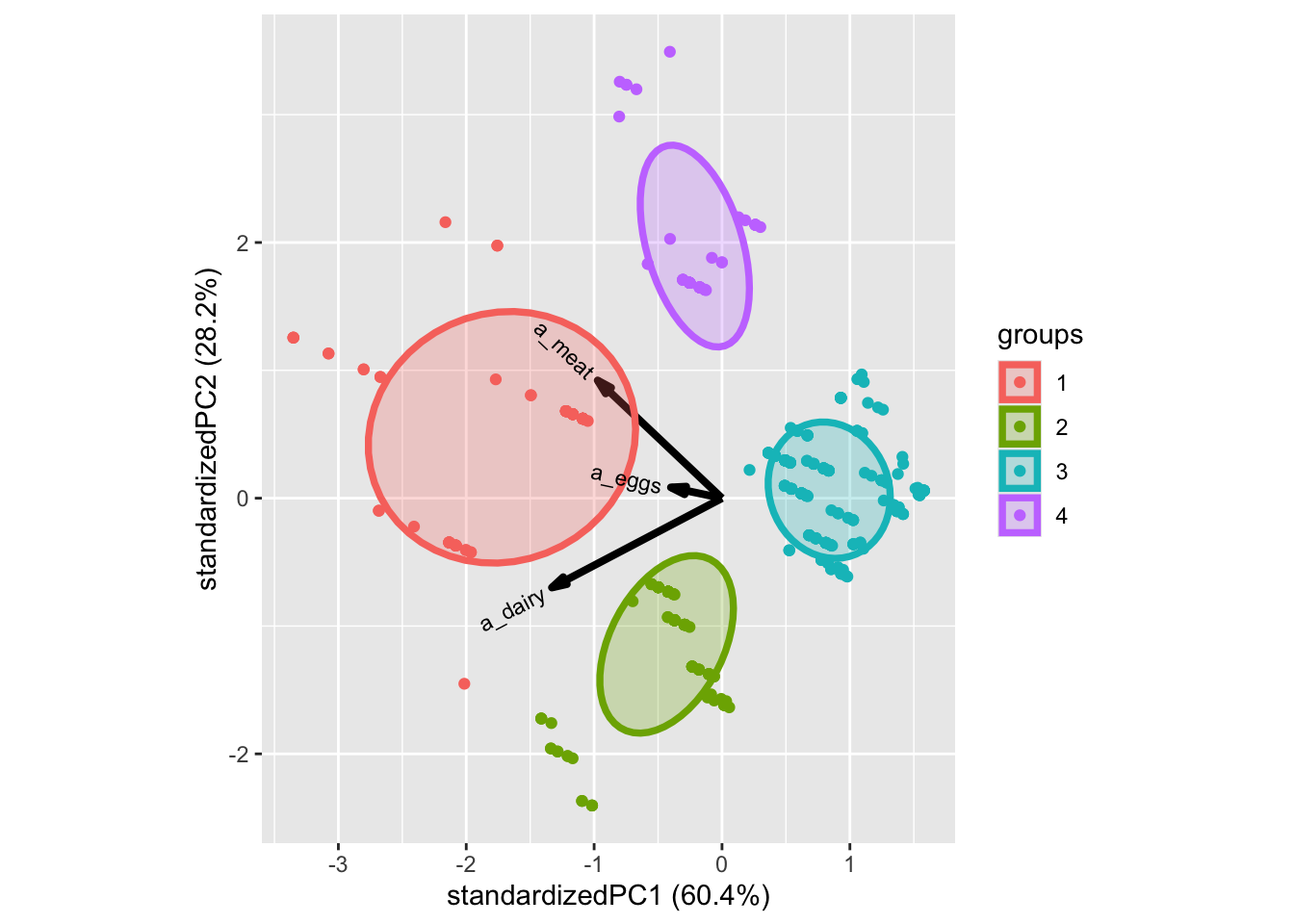
10.3.3 Add to dataset
As the clustering is a characteristic for each sample, similar to age, gender, name,… we can simply add it to the dataset. Here the interpretation from above gives rise to some intuitive names. These can be used directly. Here is how to add it to the dataset:
## a_meat a_dairy a_eggs
## 1 19.150000 21.850000 7.678571
## 2 4.688508 18.854839 3.601815
## 3 3.719886 5.167045 2.915909
## 4 18.812500 5.729167 4.492188#Then matched the label names, according to the plot above.
plantbaseddiet$clusters <- factor(res$cluster,labels = c('High Meat','Low All','High Dairy','High All'))
#And here the plot, now with the right labels.
ggbiplot(PCAmdl, groups = plantbaseddiet$clusters, ellipse = T)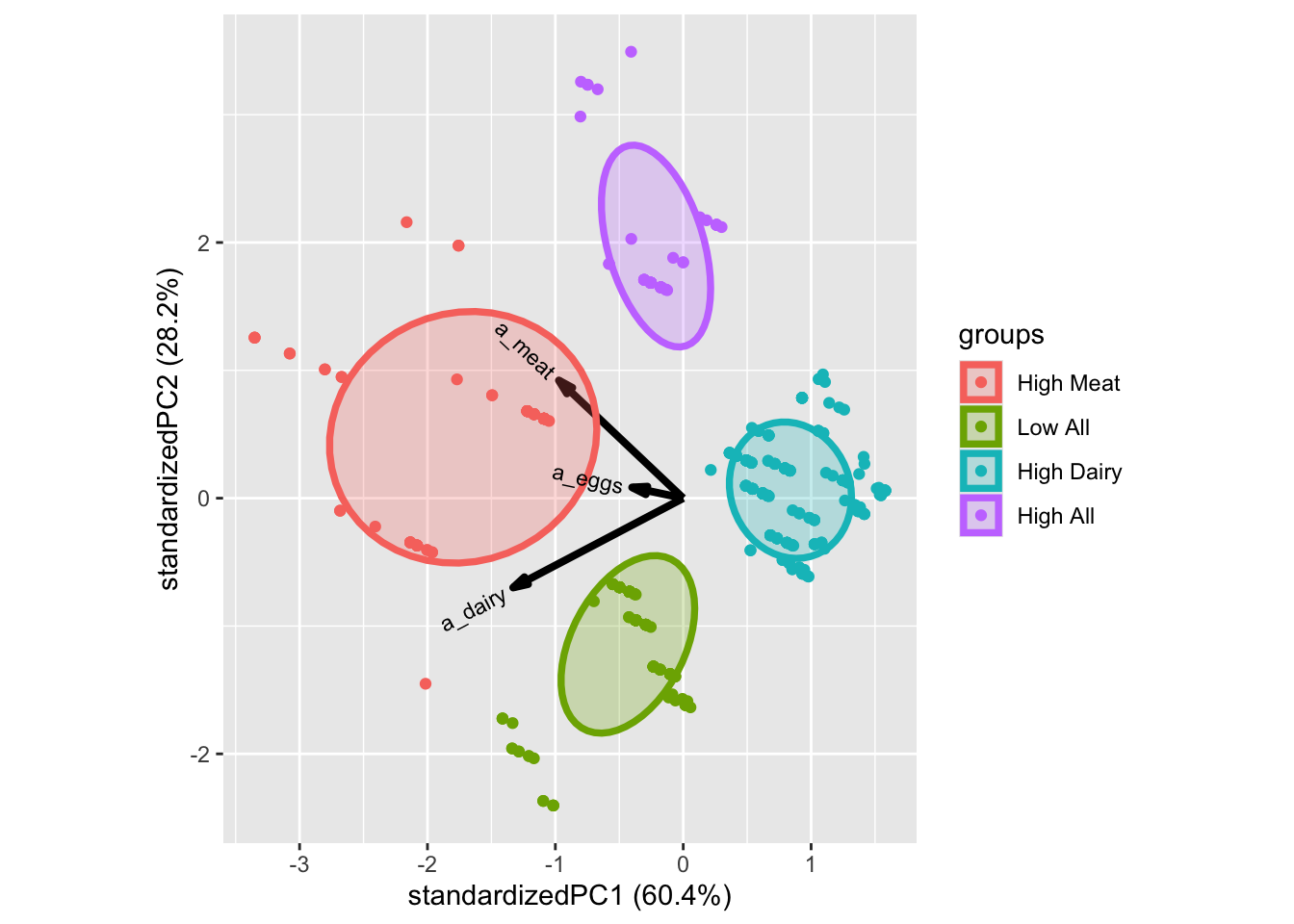
10.3.4 Comments
Try to investigate if the number of clusters using gab-statistics and extract between and within variances.
Plot the different versions using PCA.